WordEater is a project I did last year using ml5.js to capture hand movement to generate sentences from a list of words.
After its initial version, I have updated the website multiple times – The initial version used face tracking and mouth movement, but due to issues related to face recognition and COVID mask mandation, now it uses hand movement to capture and generate words.
The ingredients, or ‘seeds’ for word generation uses words from a headline article from the New York Times at some day in December 2020. While I intended to update the list of words frequently, I didn’t implement any API integrations in my previous project. While learning about API integrations, I decided that this was a good chance to use the New York Times API to get the latest info about daily headlines automatically.
Most Viewed API
Fortunately, the NYT API provides a fairly easy way to sign up. If you sign up at https://developer.nytimes.com/apis , you can gain direct access to NYT APIs without getting any extra permission from them.

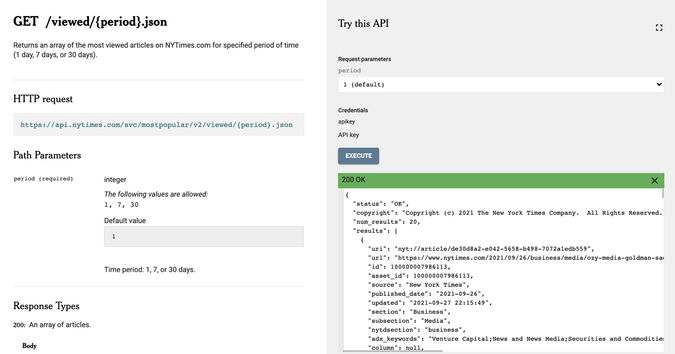
I used the Most Viewed Articles API to get a JSON data of the most viewed article in the New York Times. Although the API didn’t provide the actual article’s content, the metadata included article abstracts – which was enough for me to generate a list of words that can be used as an ingredient for random sentence generation.
Integrating the NYT API to my old project
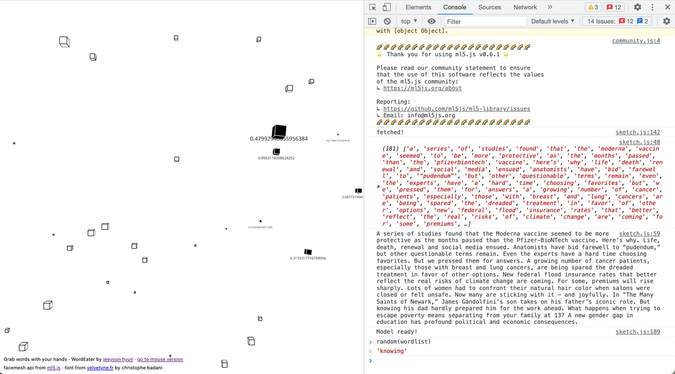
First attempt
Although I succeeded fetching the abstract of 10 most viewed articles in the New York Times daily, I failed integrating them in my website. Due to unknown reasons, my website, which is supposed to bring random words from a list, is showing only a bunch of random numbers.
Troubleshooting
After looking into the issue, I found out that this was because of the order of the fetch() API being executed. Since I was assigning the randomly generated words to the particles before I was even getting them from the API, my website was showing just random numbers instead of random words. I fixed this issue by changing my code’s order, by letting the particle generation & word assign code to be executed AFTER I actually fetch my API.
Don’t forget hiding the API Key
Automated bots on the Internet can always attack random Github repos and take your API Keys. I unfortunately learned this lesson in a hard way a few years before when my AWS account was compromised, resulting a $1,000 bill in my account (Fortunately, I resolved this issue through customer service).
This article has an easy explanation about how to hide API keys or sensitive information when uploading a project to a Github repo. There is also a Github article about best practices when uploading sensitive data to a repo. Following this article, I made a separate config file and stored my API key there.
One problem is since I was using Github pages to deploy my website, all of my assets had to be public if you wanted to publish a site. I am thinking about changing my website hosting method because of this issue. Alternatively, this stackoverflow thread also explains how to use dotenv and creating a new gh-pages branch.
You can finish seeing the in-progress version at https://jeeyoonhyun.github.io/WordEater/ . Try opening the console if you want to see which headlines I’m calling from the NYT API.