- Link to webcam version: Move your hands and pinch cubes to select words and generate sentences.
- Link to mouse version: Move & click your mouse to generate sentences.
Update (Jan 2021): WordEater has multiple versions. The previous version used mouth as a controller. However, due to concerns with face recognition technology and COVID-19, I changed the controller to use hands instead.
Demo video
Overview
Ever felt confused of so many words floating around the Internet?
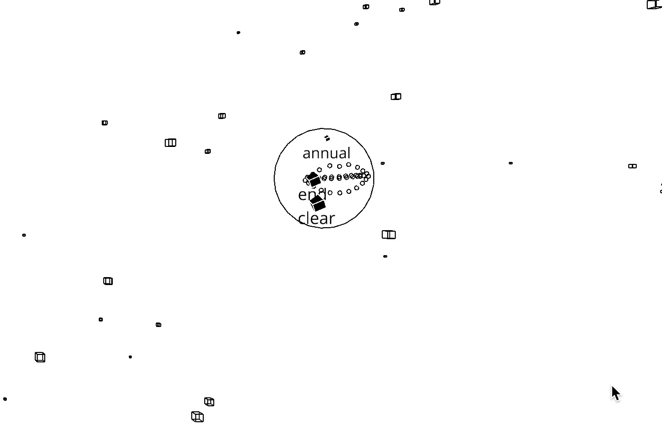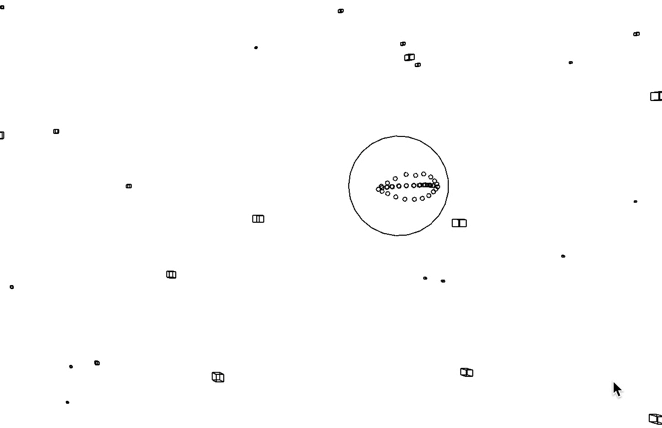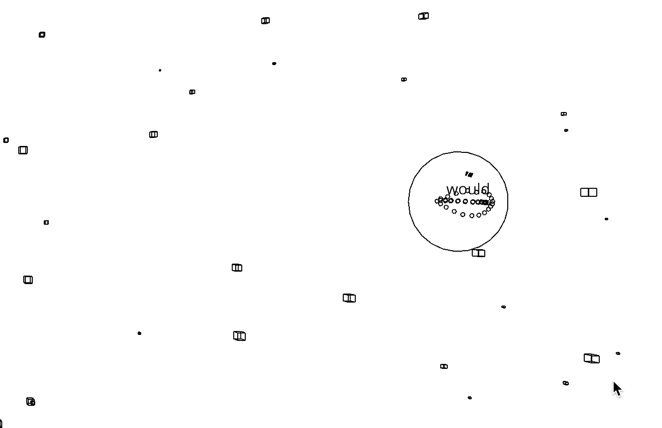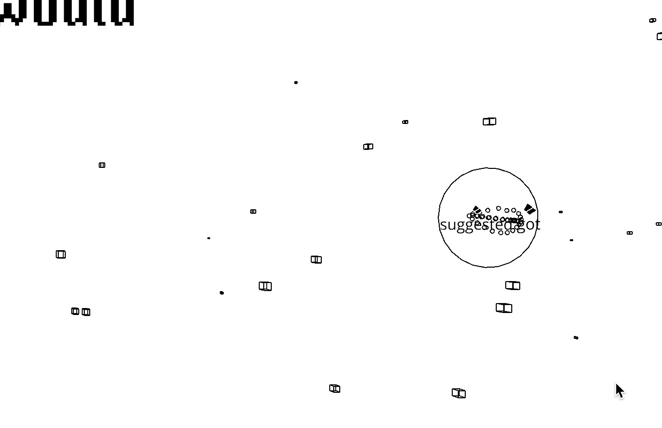
WordEater is a web based game that lets you gobble up a bunch of meaningless words in order to make another meaningless sentence, eventually removing all words that you see in the screen.
It doesn’t matter if you don’t understand what the words or sentences are trying to say – after all, they are going to be swallowed and eaten anyway. All you need to do is get some peace of mind by consuming all the disturbing, shattered pieces of information that makes complete nonsense. The goal of the game is making your web browser more cleaner by scavenging fragmented data with your mouth.
After all, your web browsers also need some refreshment from the gibberish they encounter everyday!
WordEater uses the Facemesh API in ml5.js to detect your hands in your webcam. You can play the mouse version if you can’t use your webcam.
Ideation
I started brainstorming, but I couldn’t settle to one idea – it seemed that I had so much things that I wanted to try. Because of this, I decided to implement the parts that I wanted to do and add elements as I go on.

I started with cloning my previous homework that I did for the Machine Learning for the Web class which used the Facemesh API in ml5.js. It was interesting to see the final output to be completely different from the code that I reused.
How it works
Particles
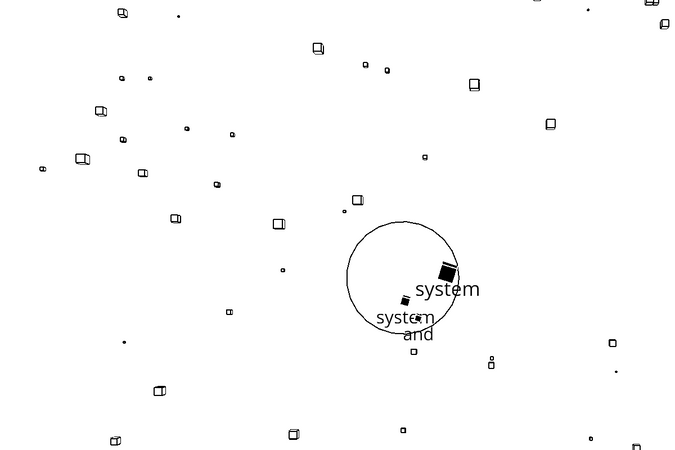
I used the WEBGL mode in p5.js and made some particles of cubes. The cubes are supposed to 1)change color and 2)disappear when the controller clicks them. I also made the particles to be enlarged when the controller is near the particles.
Mouth version: Using the Facemesh API



I deleted all the other coordinates in the ml5.js Facemesh API and only left the coordinates in lipsUpperOuter, lipsLowerOuter, lipsUpperInner and lipsLowerInner. This enabled me to project a realistic capture of the webcam’s mouth.
Sentence generation
I originally intended to user the Markov Chain method we used in the class to generate a plausible sequence of words from a given paragraph. However, due to time constraints, I adapted to choosing random elements from a given array of words.
A random word from the New York Times’ most viewed article API is assigned to each particle. When the user clicks the screen, the particles that are inside a certain radius of the controller disappear. The words that are assigned to a particle is saved to an array, and a new sentence from the appears to the screen.
Update (Oct 2021): I eventually implemented the Markov Chain text generation method, using abstracts from the most viewed articles in New York Times. Check out this post and this post if you’re curious about how I implemented this feature.
Mouth recognition
While the mouse version can generate sentences by clicking on the word particles, the webcam version recognize when the user’s lips are shut. I calculated the distance between the Facemesh API’s lipsUpperInner and lipsLowerInner coordinates to harvest the floating words when the distance is less than a certain value.
Futher challenges
Adding musical interactions
My initial idea was to generate some sounds when a word was added to the sentence, but I couldn’t implement it because of time. I wish to develop this project further and make it as a more complete game with sound interactions.